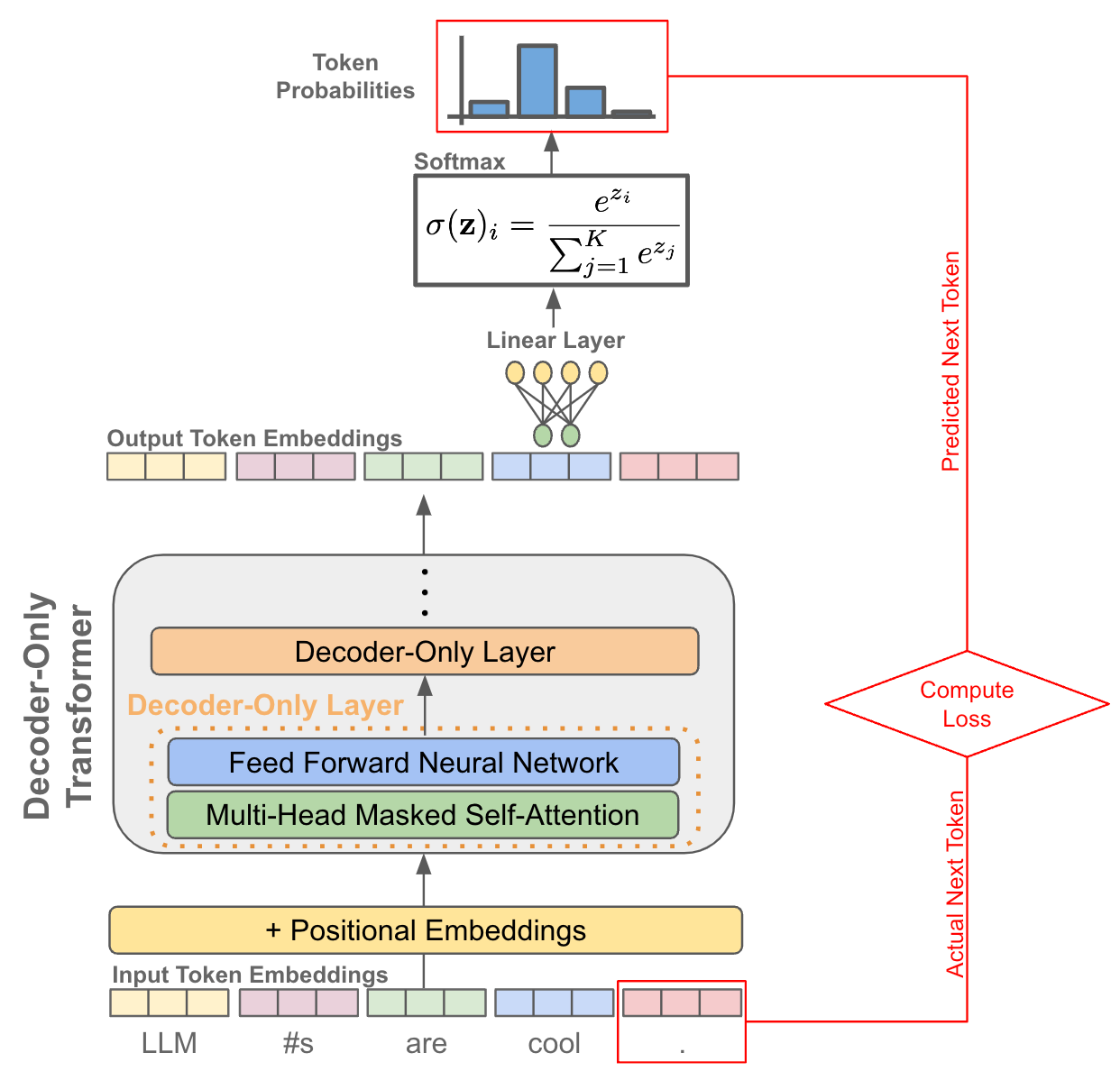
Basics of Reinforcement Learning for LLMs
When we talk about training large language models (LLMs), most people immediately think of supervised learning—feeding a model lots of examples and letting it learn from labeled data. But there’s another, increasingly important approach: reinforcement learning (RL), and more specifically, reinforcement learning from human feedback (RLHF).
What is Reinforcement Learning?
At its core, RL is about learning through trial and error—much like how we humans learn new skills. Imagine a child learning to ride a bike: they try, wobble, maybe fall, but gradually get better as they receive feedback (sometimes in the form of scraped knees!). In RL, an agent (the learner) interacts with an environment, takes actions, and receives rewards (positive or negative) based on those actions. The goal? Maximize the total reward over time.
Why Not Just Use Supervised Learning?
Supervised learning is great when you have clear, labeled data. But what if the feedback is more subjective—like a human saying, "I prefer this answer"? Or what if the reward comes much later, after a series of actions? That’s where RL shines. It lets us optimize for goals that aren’t easily captured by simple labels.
How Does RL Work for LLMs?
In the context of LLMs, RL is often used after initial supervised training. The model generates responses, and humans (or sometimes other models) provide feedback—ranking, scoring, or otherwise evaluating the outputs. The model then updates its behavior to produce more helpful, honest, or safe responses, based on this feedback. This is the essence of RLHF.
A Peek Under the Hood: Markov Decision Processes
RL problems are often described using something called a Markov Decision Process (MDP). Don’t let the jargon scare you! An MDP is just a formal way to describe the agent, the environment, the possible actions, the rewards, and how everything changes over time. The agent’s goal is to learn a policy—a strategy for choosing actions that maximize rewards in the long run.
Why Does This Matter?
RL lets us teach language models to do more than just mimic data—they can learn to align with human values, avoid harmful outputs, and even become more creative or helpful. It’s a powerful tool for making AI not just smarter, but also safer and more aligned with what we want.
Final Thoughts
Reinforcement learning is a fascinating, sometimes underappreciated, part of the AI toolkit. As LLMs become more central to our digital lives, understanding RL—and how it helps models learn from human feedback—will be key to building better, more trustworthy AI systems.